India-specific legal AI is not a niche product category. It is a direct response to a structural mismatch that has become increasingly visible as enterprise legal teams deploy AI tools at scale: the tools that dominate global legal AI rankings were built for a different legal system, in a different language, under a different regulatory framework.
The mismatch matters because legal AI is only as useful as the legal environment it understands. A tool trained on US case law and English-language contracts drafted under New York governing law produces different outputs when applied to Indian contracts governed by the Indian Contract Act, executed under multi-state stamp duty regimes, and subject to regulatory oversight from bodies like SEBI, RBI, and IRDAI. The outputs are not merely imprecise. They are structurally misaligned with the Indian legal context in ways that create real compliance risk.
Generic AI tools trained on global or public datasets often lack the structured understanding required for Indian legal research. They tend to produce hallucinated outputs that do not meet the accuracy standards legal practice demands. India-specific legal AI addresses these gaps by grounding responses in authoritative Indian legal sources and ensuring that outputs remain accurate and traceable.
This blog examines what makes India’s legal environment distinct, where generic tools fall short, and what India-specific legal AI does differently for enterprise legal teams.
Why India-Specific Legal AI Is Not Just a Localisation Exercise
The instinct when evaluating AI tools for non-US markets is to think of localisation as a configuration exercise: update the date format, add a few jurisdiction-specific templates, and the tool works everywhere. For legal AI, this framing is wrong.
Indian enterprise legal work is not American legal work with different place names. It involves a distinct statutory framework, a distinct judicial hierarchy, a distinct regulatory architecture, and a distinct set of commercial practices. Each of these requires specific training data, specific model configuration, and specific workflow integration. None of them are addressed by localising a US-trained model.
India’s judicial hierarchy is multi-layered and jurisdiction-specific
India’s multi-layered judicial structure, diverse legal sources, evolving jurisprudence, and contextual nuances demand a more specialised approach. Legal research in India requires understanding not only the law but also jurisdictional authority, precedential value, and procedural context.
A legal AI tool that does not understand the distinction between a Supreme Court judgment, a High Court judgment, and a tribunal order, or that cannot identify whether a District Court decision carries precedential weight in the context of a specific type of dispute, is producing outputs that require manual verification before they are usable. For enterprise legal teams managing high volumes of matters across forums, this verification overhead defeats much of the efficiency gain AI is supposed to deliver.
India’s regulatory framework is dense, sector-specific, and frequently updated
Enterprise legal teams in India operate under simultaneous regulatory obligations from the Companies Act, GST legislation, sector-specific frameworks from RBI, SEBI, IRDAI, and TRAI, and an evolving data protection regime under the DPDPA. These frameworks are not static. They change through notifications, circulars, amendments, and judicial interpretations at a pace that outstrips the training data of any model not specifically designed to track Indian regulatory developments.
A generic AI tool trained on a snapshot of global legal data has no mechanism to know that the RBI issued new Digital Lending Directions in May 2025, or that IRDAI’s Fraud Monitoring Framework Guidelines came into force in April 2026, or that specific stamp duty rates changed in a particular state. An enterprise legal team relying on that tool for regulatory guidance is operating with outdated information, without knowing it is outdated.
India’s contract environment has specific conventions
Indian commercial contracts follow drafting conventions, use statutory references, and include clause types that are specific to the Indian legal system. Stamp duty clauses referencing specific state stamp acts. TDS deduction provisions under the Income Tax Act. MSME payment obligation clauses. Arbitration clauses referencing the Arbitration and Conciliation Act, 1996. Force majeure clauses drafted with reference to Indian courts’ interpretation of the doctrine.
A contract AI tool that has not been trained on a large corpus of Indian contracts will extract and analyse these clauses less accurately than one that has. The accuracy gap is not theoretical. It shows up in clause identification, deviation flagging, obligation extraction, and risk scoring — the core outputs that enterprise legal teams rely on for contract review and portfolio management.
Where Generic Tools Fail in Indian Enterprise Legal Contexts
Contract review accuracy on Indian agreements
Generic AI contract review tools, most of which were developed by US or UK companies and trained primarily on English-language Western contracts, produce lower accuracy on Indian commercial agreements. The reasons are structural.
Indian contracts use different indemnification structures, different termination trigger formulations, and different warranty conventions than their US equivalents. They include provisions with no direct Western equivalent, such as stamp duty compliance clauses and specific statutory payment obligations. They reference Indian statutes, Indian regulatory bodies, and Indian courts by name. A model trained on Western contracts has to extrapolate when it encounters these provisions, and extrapolation in legal AI produces the hallucinations that make output unreliable.
For enterprise legal teams reviewing hundreds of incoming contracts per month, even a small reduction in accuracy per contract compounds into real review overhead. The time saved by AI-assisted review is partly or wholly consumed by the additional verification required when the AI output cannot be trusted without checking.
Regulatory compliance flagging
Enterprise legal teams use AI to flag regulatory compliance obligations in contracts. A supplier contract may contain obligations under the MSME Development Act requiring payment within 45 days. A services agreement may include data processing provisions that need to be assessed against DPDPA obligations. A financial services contract may reference obligations under RBI or SEBI frameworks.
Generic AI tools do not reliably identify these India-specific regulatory references, because they were not trained to look for them. They flag what they recognise, which is US and European regulatory frameworks. Indian regulatory obligations that fall outside their training data are missed, which means the legal team’s regulatory review is incomplete without additional manual checking.
Stamp duty identification and routing
India’s stamp duty framework is one of the most operationally complex aspects of commercial contract management in the country. Stamp duty rates, instrument classifications, and execution formalities differ across 25-plus states. The applicable duty on the same contract type can differ considerably between Maharashtra and Karnataka, or between Delhi and Tamil Nadu.
Generic AI CLM tools do not have India-specific stamp duty models. They cannot identify which stamp act applies to a specific instrument, what rate is applicable in a specific state, or whether the execution formality requirements of a particular state have been satisfied. For enterprises executing contracts across multiple Indian states, this is not a minor gap. It is a compliance function that the AI cannot perform and that must be handled entirely outside the tool.
Data residency and DPDPA compliance
India’s Digital Personal Data Protection Act, 2023 creates specific obligations around where personal data of Indian citizens is processed and stored. For enterprise legal teams using AI tools that process contract data, the data handling practices of the AI platform are a compliance consideration, not just a security one.
Platforms that are enterprise-grade, DPDP compliant, and hosted in India offer a capability that differentiates India-built solutions from global ones. Most US-headquartered legal AI vendors process data on servers outside India. For enterprises in banking, insurance, and financial services, where sector-specific data localisation requirements add to the DPDPA baseline, this creates a direct compliance risk.
What India-Specific Legal AI Does Differently
Training on Indian legal data at scale
Legal AI built specifically for Indian law is trained on structured legal data and understands the hierarchy and relationships between courts, statutes, and regulatory bodies. This is the foundational difference. A model trained on Supreme Court judgments, High Court judgments, tribunal orders, NCLT and NCLAT decisions, regulatory circulars from RBI, SEBI, IRDAI, and TRAI, and a large corpus of Indian commercial contracts will produce outputs that are structurally aligned with the Indian legal context.
This alignment shows up in accuracy on Indian clause types, in the ability to identify India-specific regulatory obligations, in the quality of legal research outputs linked to Indian precedent, and in the reliability of risk flagging on Indian contract portfolios.
India-specific regulatory tracking
India-specific legal AI platforms maintain live tracking of regulatory developments across the frameworks that matter to Indian enterprise legal teams. When the RBI issues a new circular, when SEBI updates its listing obligations, when a state stamp act is amended, the platform incorporates this development into its regulatory knowledge base. The legal team is working with current information, not a static snapshot.
This continuous regulatory tracking is the difference between an AI tool that supports compliance work and one that creates compliance risk by providing outdated guidance.
India-specific workflow integration
Enterprise legal teams in India use workflows that are specific to the Indian legal environment: multi-state stamp duty assessment and payment, India Post integration for physical notice dispatch, integration with Indian court systems for case status tracking, and eSign workflows using Aadhaar eSign and DSC. India-specific legal AI platforms are built to integrate with these workflows natively.
For teams who need India-specific statutes, GST/Income Tax, Companies Act and SEBI coverage, India-hosted and DPDP-aware platforms make a practical first stop for legal and finance teams who need a reliable research and drafting assistant.
Language and multilingual contract handling
Indian enterprise contracts are not uniformly English-language. Contracts with state government bodies, regional vendors, and counterparties in specific sectors often include Hindi-language schedules, bilingual main agreements, or entirely regional-language documents. Generic AI tools have limited capability on Indian regional languages, which means contracts that include non-English sections produce lower accuracy outputs.
India-specific legal AI platforms built with Indian language training data handle multilingual contracts more reliably, which matters for enterprises operating across states where regional language contracts are standard.
The Business Case for Enterprise Legal Teams
The argument for India-specific legal AI is not primarily about patriotism or vendor geography. It is a performance argument. A tool that produces more accurate outputs on Indian contracts, covers Indian regulatory frameworks, handles India-specific workflows, and stores data in India delivers more value to an Indian enterprise legal team than one that does not, regardless of where either tool was built.
Legal tech funding grew year-over-year by 44 percent, reaching an estimated USD 3.56 billion in the first half of 2025. Global investment in legal AI is accelerating. Much of that investment is going into US and European platforms. But the Indian legal market is distinct enough that global scale does not automatically translate into Indian-market performance. Enterprise legal teams that choose platforms on the basis of global brand recognition, rather than India-specific performance, are making a procurement decision that will show up in reduced accuracy, increased verification overhead, and compliance gaps that the AI was supposed to prevent.
The evaluation standard for legal AI in an Indian enterprise context should be: does this tool understand Indian law, Indian regulatory frameworks, Indian contract conventions, and India’s data governance requirements? If the answer is not clearly yes, the tool is not ready for Indian enterprise legal operations.
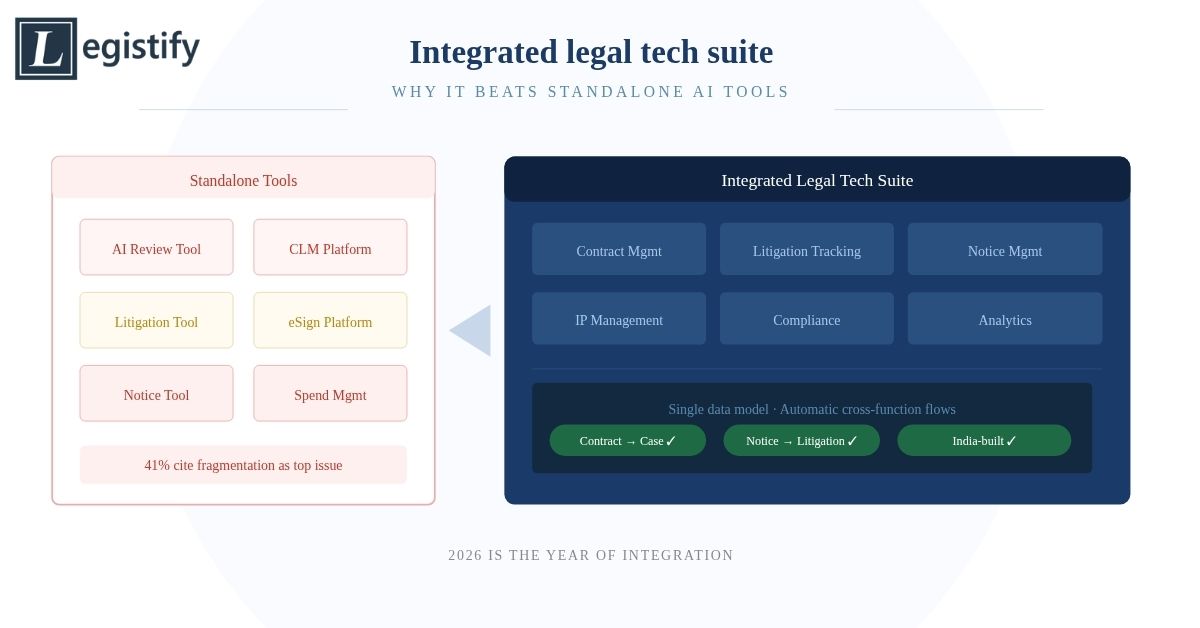
Legistify is built specifically for the Indian enterprise legal environment, with contract management, litigation tracking, and notice management capabilities designed around Indian law, Indian regulatory requirements, and Indian legal workflows.
Conclusion
India-specific legal AI is not a premium feature or a market-specific variant of a global product. It is the baseline capability that an AI tool needs to be useful for enterprise legal teams operating in India. Generic tools built on global training data, without specific knowledge of Indian law, Indian regulatory frameworks, Indian contract conventions, or Indian data governance requirements, require human verification to be usable in the Indian context.
As AI becomes a standard part of enterprise legal operations, the gap between tools that understand the Indian legal environment and those that do not will become more visible in legal team performance, compliance standing, and operational efficiency. Choosing AI for Indian enterprise legal work on the basis of global reputation rather than India-specific performance is a decision that creates ongoing costs that are easy to underestimate and difficult to fix.